
We've just released Version 2.14 of the syllabus dataset, which adds 5.2 million syllabi to the collection and brings the topline numbers to:
- 32.9 million syllabi
- 8620 colleges and universities represented.
- 156 schools with over 50,000 syllabi.
- 94 million citations of
- 4.4 million unique titles
For comparison, our 2.10 dataset, release 2 1/2 years ago, topped out at:
- 18.9 million syllabi
- 7900 schools
- 75 with over 50,000 syllabi
- 56 million citations of
- 3.4 million titles
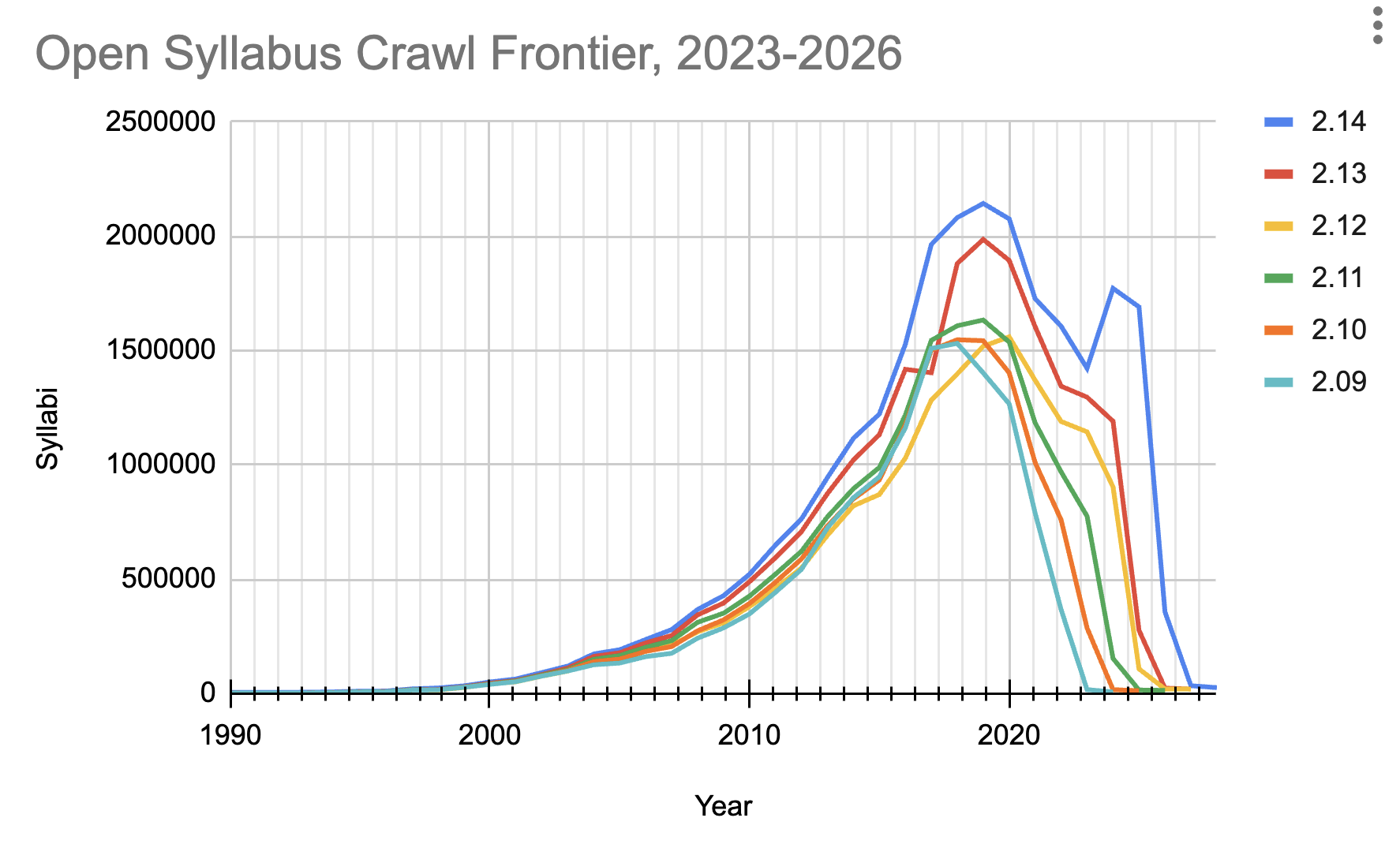
New versions of the dataset usually include more syllabi collected, more discoverable titles, better deduplication, and better overall quality of the extracted sections. This is a big part of the work of building and curating the largest archive of teaching materials in the world. Syllabus numbers grow as new terms become available, but also as we intermittently revisit the roughly 10,000 schools we track over time. We also invest in collecting from older sources, which slowly expands the historical dimension of the collection. In practice, this means that the collection peak is always several years behind the current year. Currently, that peak is 2021. Taken together, these factors produce a 'crawl frontier' that traces the the growth of the collection over time.
There are two other developments that might be worth sharing since they affect how we provide access to data. One is the growth of third-party scraping of OS Analytics -- both the free version and attempts to scrape via spam trial accounts. As a scraping-based archival project, we have a lot sympathy for scraping as a baseline feature of the open web. But we are seeing very significant growth in scraping that, in the past year, has come close on several instances to bringing down OS Analytics. This is not a problem specific to Open Syllabus. A recent Charleston conference panel of open data service providers put the percentage of traffic from bots to their sites at 86%. Waves of AI bot scrapers produce a drain on engineering resources and, of course, our sustainability model around the dataset. And it's why, since March, if you visit Analytcs, you'll experience one or more Cloudflare prompts that try to separate the humans from the bots. I see no reason to think that this will stop, and some reason to fear that it will force open services further behind authentication walls.
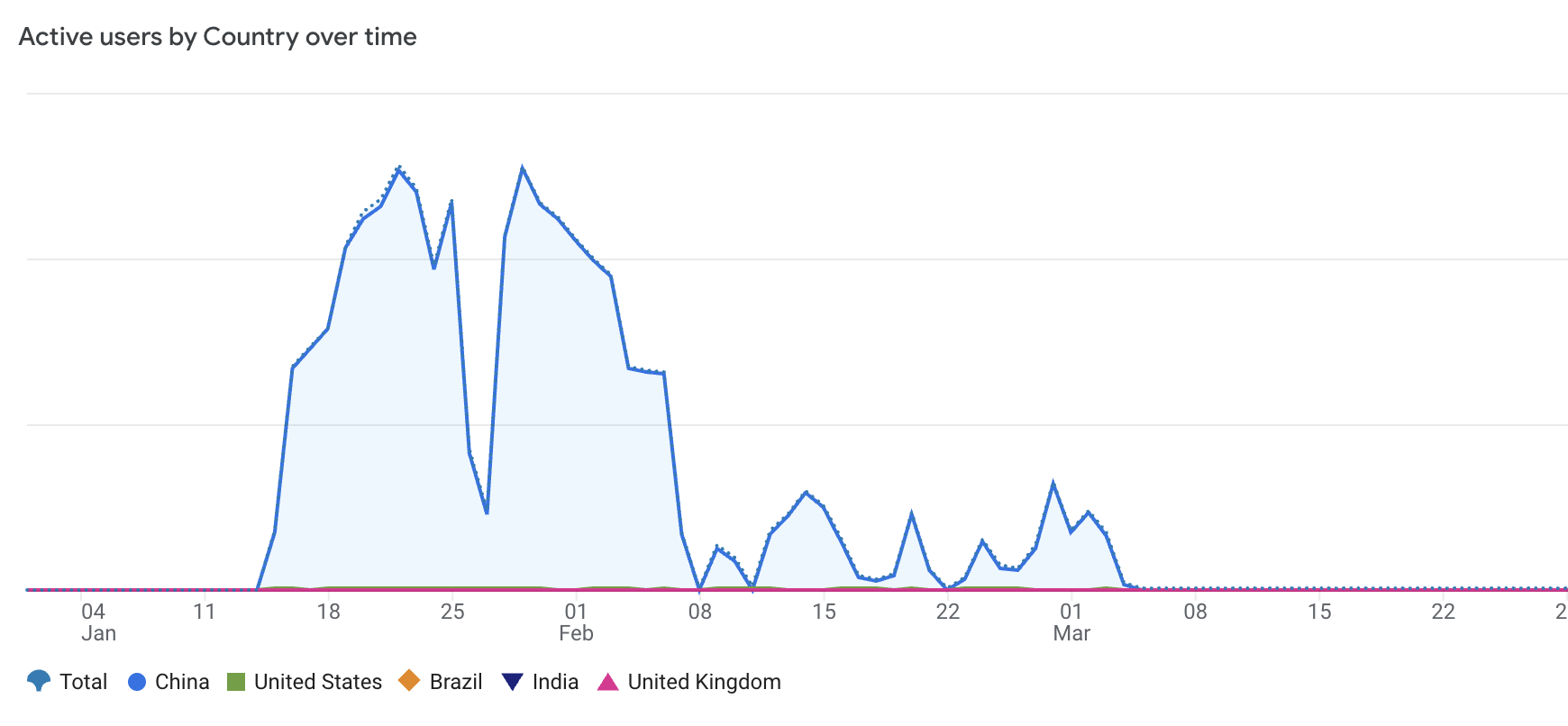
Yes, that red line at the bottom is our normal traffic compared to recent (China sourced) scraping efforts.
The other development is the growth in the number of data requests, mostly from researchers, that come into Open Syllabus. What in past years was a more-or-less once a month pace has increased to several per week and sometimes more. Since each of these leads to a conversation, written agreement review by counsel, involvement of engineers, usually a payment, and often follow up, the higher numbers have been hard to manage for our small team. If you've experienced this personally in the form of slow follow ups or deferred answers, I apologize. Now you know why. The answer -- at least a partial answer -- will be coming shortly in the form of a large open "CC-NC" data release. More on that to come.
In the meantime, we're launching our Spring 2026 Account Jubilee, which will give all existing (expired) trial accounts renewed access through June 8. If you've been missing your full account access, enjoy.